CU-STATUN3106-image-memorability
Columbia University - STATUN3106 - Applied Machine Learning - Spring 2026 - Final Project
Benji Barnes, Beccan Gruenberg, Kayla Jiang, Mason Lau
What makes an Image Memorable?
Assesing if a CNN relies on human-interpretable features in the MIT Large-scale Image Memorability (LaMem) dataset
GitHub Repo
github.com/beccangruenberg/CU-STATUN3106-image-memorability
Compiled Notebook
Data Folder
Google Drive Folder (LionMail Only)
Project Blog
github.beccan.gruenbergs.net/CU-STATUN3106-image-memorability/
Image Memorability Analyzer
Prototype Blog
github.beccan.gruenbergs.net/CU-STATUN3106-image-memorability/prototype
Blog Post
Introduction

These are some of the first images that pop up when you type “Top 10 Most Famous Images of All Time” on Google. Why are they so flipping iconic? Is it the strangeness of those awkward drooping clocks in Dalí’s The Persistence of Memory? Is it the way in which a naked child running from danger evokes some sort of primal terror alert in us? Is it the awesome color contrast between Muhammad Ali’s red gloves and crisp white shorts? Or is it maybe even the fact that Bertie’s tongue simply forces us to giggle? Whatever the reason, these images are unbelievably sticky. And yet, most people would struggle to recall the last Instagram Reel they watched, or any one of the billboards they drove past on the way to work this morning. So then, why are some images more memorable than others?
In this project, we approach the problem computationally. We train a convolutional neural network (CNN) on the Large-Scale Image Memorability (LaMem) dataset to predict a memorability score for any given image. We then ask a deeper question: what visual features actually drive these predictions? To investigate this, we conduct a targeted ablation study that systematically blurs human faces and measures the resulting shift in predicted memorability scores. We pair this with Grad-CAM visualizations, which reveal which spatial regions of an image the model attends to when forming its prediction. Finally, we package the full pipeline into an interactive Gradio interface that allows any user to upload a photo and receive a memorability score alongside an attention heatmap and a blurred-face comparison.
Together, these three components turn the CNN from a black box into an empirical instrument. We’re not just asking how memorable is this image? We’re asking what is the model looking at when it decides? The central question of our project is binary: does the model rely on human-interpretable features - faces, emotional content, salient objects - or does it reach the right memorability score through shortcuts like colour distributions, background patterns, and low-level textures? If it’s the former, our model is a window into human memory; we can validate decades of cognitive science findings and potentially even use it as a tool in industry. If it’s the latter, that’s interesting too - it means not only the model has found a shortcut, but that we may have even been wrong about what makes an image stick in the first place. Either way, we walk away with something we didn’t have before: a testable, mechanical account of memorability. The potential impact of this is profound. A memorable anti-smoking ad changes whether a teenager picks up a cigarette. A memorable evacuation diagram changes whether someone gets out of a burning building. A single photograph (for example, a nine-year-old fleeing a napalm strike) helped turn American public opinion against the Vietnam War. If we can predict and explain what makes an image memorable, we can more easily build the ones that need to stick - public health campaigns, humanitarian appeals, classroom materials, safety warnings. Today, the people designing those campaigns are largely working on instinct. This project produces a model that can tell them what works, and why.
Background
At the heart of our investigation lies a fascinating cognitive truth: memorability is not a flighty, subjective whim, but an incredibly consistent property of the images themselves. As demonstrated in the landmark study by Isola et al. (2011), disparate viewers tend to remember and forget the exact same images at remarkably similar rates. This suggests that the “stickiness” of a visual is an intrinsic characteristic of the image, rather than a byproduct of who is looking at it. Consider, for instance, the presence of human faces - perhaps the single most robust predictor of memorability ever identified. Our brains even possess dedicated neural machinery, the Fusiform Face Area (FFA), specifically tuned for facial perception and recognition. When faces appear, the FFA “lights up” in fMRI scans, and this selective processing power seems to translate directly into memory retention (Kanwisher et al., 1997). Beyond faces, several other primary visual drivers reliably signal the brain to pay attention and encode, as summarized in the table below:

While the table above provides a tidy summary of visual “stickiness”, the literature is actually rife with fascinating contradictions. The first is typicality. Some studies argue that atypical, unusual content is more memorable (Bainbridge et al., 2013). Others find the opposite - that typical images are remembered better than unusual ones (Vokey & Read, 1992). The second is emotion. While it is true Khosla et al. (2015) found images depicting fear and disgust score higher than neutral ones, the broader claim that emotional arousal is a major driver of memorability is heavily contested. Wakeland-Hart & Aly. (2025) ran the most recent test and found that valence and arousal accounted for less than 8% of the variance in memorability scores. So emotion contributes, but it’s nowhere near a primary engine. Hopefully the model we build can help provide some clarification on the role typicality and emotional valence play in memorability.
Now we pivot to the second core part of our project. To do this, please picture the following situation. You’re a hospital administrator. A team of researchers presents you with an AI model that detects pneumonia from chest x-rays. On the test images they show you, it gets the answer right almost every time - comfortably better than a junior doctor, and in the same ballpark as an experienced radiologist. The paper is published in a respected journal. You decide to buy the system, deploy it at your own hospital, and start running it against the x-rays coming through your radiology department. Within weeks, the system produces spectacularly incorrect results. Patients without pneumonia are flagged as having it. Patients with obvious pneumonia are missed. Why?
In 2018, Zech et al. answered this question with a striking diagnosis: the model wasn’t reading lung pathology, it was reading watermarks. Training CNNs on 158,323 chest x-rays from the NIH, Mount Sinai, and Indiana University, they found that performance collapsed on data from new hospitals. Saliency maps revealed why. The model had latched onto things like the metal tokens radiographers place at the edge of films, the orientation of the “L” and “R” laterality markers, image-processing signatures specific to each scanner, and even the visual hallmarks of portable x-ray equipment (used when patients are too sick to leave bed, and therefore correlated strongly with disease). Once the CNN could identify which hospital an image came from, it simply applied that hospital’s base rate of pneumonia as a shortcut to get the correct answer.
This phenomenon is known as shortcut learning. While it is well established in standard vision tasks (Geirhos et al., 2020), it remains completely unknown whether the same issue occurs when models are trained explicitly on human memorability. This distinction is crucial: if a CNN trained on LaMem relies on shortcut cues, then it is not representative of how humans remember images, but instead depend on dataset-specific correlations. Any conclusions about “what makes an image memorable” would therefore be misleading. If, on the other hand, the model relies on human-interpretable features and ranks their importance in a way that matches what humans actually find memorable (e.g. face > color contrast > salient objects), then two things follow. First, we can validate longstanding behavioural findings (Isola et al., 2011) with a new methodological lens. Second, we can translate these predictions into real-world tools with confidence that they’ll generalise. Distinguishing between human-aligned visual features and mere shortcuts ensures that these applications are based on genuine drivers of human memory rather than fabricated associations, preventing systems that perform well in testing from failing in real-world deployment. This problem also poses some philosophical questions regarding our relationship with artificial intelligence and the direction that it should take. How exactly do machine learning models “see”? How do they encode what they see? What, if anything, does that tell us about the way humans do the same? Should we be tuning models to replicate human perception, or treating their divergences as evidence of something we’ve been missing? This project doesn’t claim to settle these questions. But by comparing what our model attends to against what humans remember, we begin (albeit modestly) to chip away at them.
What Prior Work Has Been Done in the Area?
Computational memorability research begins with Isola et al. (2011), whose central insight is the one we anchored our project on: memorability is consistent across viewers, which makes it learnable. Their first model used hand-engineered features and was only modestly predictive. Khosla et al. (2015) introduced LaMem (60,000 images) and MemNet, the first deep CNN trained end-to-end on memorability. MemNet reached near-human predictive accuracy and is the architectural ancestor of our own model. However, the MemNet paper validated that a CNN could predict memorability well, but it did not interrogate what features drove those predictions. That is precisely the gap this project aims to fill.
The trajectory since MemNet has been one of bigger architectures and tighter prediction accuracy - most notably ResMem (Needell & Bainbridge, 2022), which swapped MemNet’s older backbone for a residual network and now sets the benchmark. ResMem is used off-the-shelf by other labs to score images for their own experiments. Yet across nearly a decade of progress, the interpretability question has been entirely sidestepped. Perera et al. (2019) neatly explained that point: they reached human-level accuracy on LaMem and asked whether memorability was therefore “solved”. Their answer was no. Hitting the target tells you a model is accurate; it doesn’t tell you it has understood anything.
One consistent and important finding across all of this early work is that humans are surprisingly bad at predicting memorability themselves. When people are asked to guess which images will be memorable, their guesses track how beautiful or interesting an image looks – not how memorable it actually turns out to be (Isola et al., 2014). In other words, an image can be stunning and immediately forgettable, or visually unremarkable and highly memorable. This disconnect between what people think makes images stick and what actually makes them stick is one of the main motivations for why our group wanted to use machine learning to study this problem.
More recently, Kramer et al. (2023) and Lahner et al. (2024) have converged on the same conclusion from very different angles. Kramer et al., using over a million memory ratings across 26,000 object images, overturned two longstanding assumptions: that brightness and color drive memorability (semantics matter more), and that atypical objects are most memorable (in fact, prototypical ones are). Lahner et al. found the neural counterpart with combined fMRI and MEG: memorable images preferentially recruit late ventral visual regions like the inferior temporal cortex and fusiform gyrus, with the response beginning around 300 ms after image onset - after high-level semantic processing has already occurred.
Taken together, this literature establishes a coherent picture: memorable images are those that engage the brain’s high-level semantic and social processing systems most deeply, with faces and people being the clearest example of stimuli that reliably trigger this response. Whether CNNs trained on memorability data have learned to approximate this same high-level semantic sensitivity, or whether they are picking up on something else entirely, is the core question our project investigates.
Project Hypothesis
In our project, we have two potential outcomes:
- Case A: The CNN achieves accurate predictions using human-interpretable features.
- Case B: The CNN achieves accurate predictions using non-human visual cues.
Our central hypothesis is that memorability predictions will depend primarily on high-level semantic content rather than low-level visual properties - but that the model may partially exploit shortcut cues alongside these.
In Case A (human-aligned learning), we expect the CNN to rely on features identified in prior work: faces, people, and meaningful objects will rank highest, and backgrounds and landscapes will contribute minimally. Specifically, we predict the feature ranking to be face > person/action > salient object > text. Under this scenario, we expect the results from our ablations should behave as follows:
- Face removal: large drop in predicted memorability.
- Background ablation: little to no effect.
- Grayscale conversion: minimal effect (color is only weakly related to memorability).
- Blur: moderate drop, by degrading semantic clarity (e.g. obscuring faces).
*Importantly, these more preliminary qualitative expectations do not necessarily map directly onto the specific ablations we decided to explore, and are more so useful from a contextual and speculative perspective.
In Case B (shortcut learning), we expect the model to rely on non-human cues such as texture frequency, background patterns, colour distributions, or image statistics. The feature ranking would shift to texture/pattern > color contrast > spatial frequency > semantic content, and the ablations should behave very differently:
- Face/person removal: little effect if background statistics remain intact.
- Background ablation: significant drop.
- Grayscale conversion: noticeable drop if color distributions are being used.
- Blur: the largest decline, by disrupting high-frequency texture signals.
Comparing the observed pattern of ablation responses against these two predicted pattern tracks lets us test directly whether the model is learning meaningful, human-relevant features or exploiting spurious correlations.
Dataset
This project used MIT’s LaMem dataset, a large-scale image memorability benchmark containing 60,000 images paired with human-assigned memorability scores obtained through behavioral experimentation. For our project, we randomly sampled a subset of 1,000 images and retained the memorability score of each image by matching the filenames to the official LaMem train, validation, and test split files. We then constructed a CSV file containing image paths and memorability scores.
We next generated modified versions of the dataset through automated preprocessing scripts written in Python. Each manipulation isolated a specific visual feature while keeping the rest of the image as unchanged as possible.
The first ablation applied Gaussian blur to each image, removing fine details and textures while maintaining the overall scene composition. The second ablation converted all images to grayscale, removing color information while preserving shape and contrast. A third ablation center-cropped each image to retain approximately the central 50% of the image’s width and height, reducing surrounding contextual information while preserving the primary subject when centrally located. This allowed us to examine whether memorability is influenced more strongly by centered objects or by the broader context of a scene.
Two semantic ablations were also implemented to study human-interpretable content. The first used MediaPipe’s machine learning–based face detection model to create a face-blur condition. Detected faces were blurred using Gaussian filtering, isolating facial information from the rest of the image. We initially experimented with OpenCV’s Haar cascade classifier, but found that it performed unreliably on angled faces and varying lighting conditions. We therefore switched to MediaPipe and lowered the face detection confidence threshold in order to capture substantially more faces, accepting a higher number of false positives in exchange for fewer missed detections. The second semantic ablation used EasyOCR to create a text-blur condition. EasyOCR is an optical character recognition model capable of localizing readable text within images. Detected text regions were blurred, allowing us to analyze whether written language contributes to memorability.
An important note on the dataset is that because both the face and text ablations rely on automated detection models, the resulting datasets are imperfect and occasionally contain false positives or missed detections.
All of our preprocessing scripts, generated datasets, and metadata files were uploaded to the project’s shared Google Drive.
Methods
To predict image memorability, we fine-tuned a ResNet-50 convolutional neural network initialized with ImageNet pretrained weights on the LaMem dataset. ResNet-50 was selected because of its strong performance on image recognition tasks and its ability to learn hierarchical visual representations through residual connections. The model was initialized with ImageNet pretrained weights in order to leverage previously learned low- and mid-level visual features such as edges, textures, and object structure.
The final classification layer of the pretrained network was replaced with a regression head designed to output a continuous memorability score between 0 and 1. The regression head consisted of a fully connected linear layer mapping the 2048-dimensional ResNet feature output to 512 dimensions, followed by a ReLU activation function, a dropout layer with probability 0.3, and a final linear layer producing a single scalar output. A sigmoid activation function was applied to constrain predictions to the same range as the LaMem memorability scores. Images were resized to 224 × 224 pixels to match the native ResNet-50 input dimensions. Standard ImageNet normalization values were applied during preprocessing. The dataset was split into 80% training and 20% validation data, corresponding to 800 training images and 200 validation images. Training was performed using Mean Squared Error (MSE) loss and the Adam optimizer with a learning rate of 1e-4. The model was trained on GPU using CUDA acceleration.
After training, the model was evaluated on both the original and ablated image datasets. For each ablation type, memorability predictions from the modified images were paired directly with predictions from their corresponding original images. Differences between original and ablated memorability scores were analyzed using paired t-tests with a significance threshold of α = 0.05.
In addition to memorability prediction, Grad-CAM visualizations were generated to examine which image regions most strongly influenced the model’s predictions. Grad-CAM was implemented on the final convolutional layers of ResNet-50 to produce spatial heatmaps highlighting the regions that contributed most strongly to predicted memorability scores. These visualizations were compared across original and ablated image pairs in order to evaluate how the model’s attention shifted after specific visual features were removed or altered.
All training, preprocessing, ablation generation, and evaluation pipelines were implemented in Python using PyTorch and related computer vision libraries.
Results
Quantitative Results
Five types of image modifications were evaluated against their paired originals across up to 1,000 image pairs: grayscale conversion, whole-image blur, face blur (targeted), text blur (targeted), and center crop. Each modification was scored by the trained model and compared to the original using a paired t-test (α = 0.05). Below we outline the observed effects for each ablation, and a full picture of our quantitative results are reported in the following summary table. We also generated charts that illustrate the per-image relationship between original and ablated scores and the overall distribution of score deltas. For organizational purposes, we’ve only included these charts for the face blur condition in this blog post, but visualizations for the remaining ablation conditions can be found in the accompanying notebook.
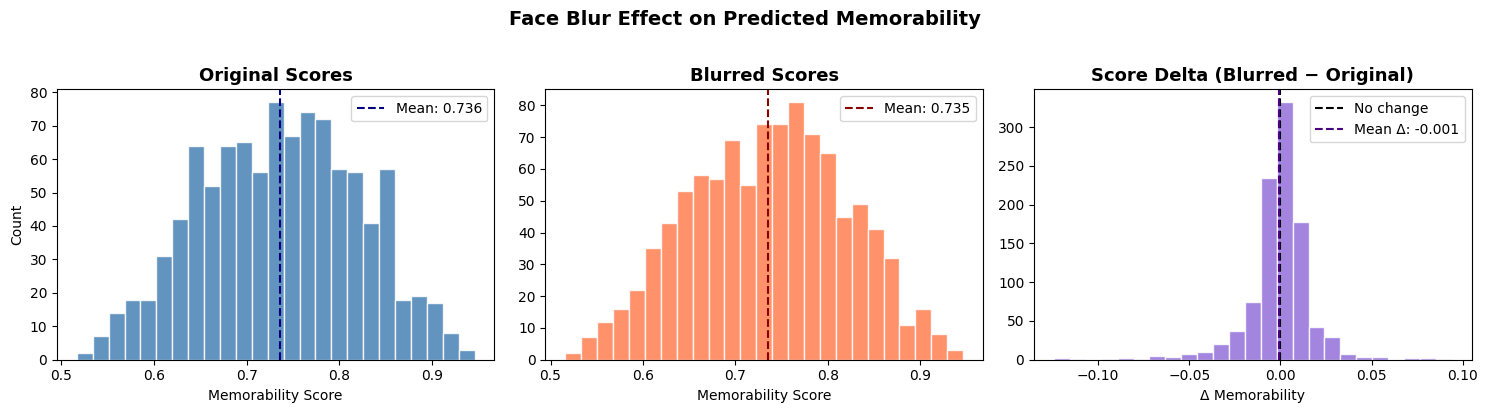
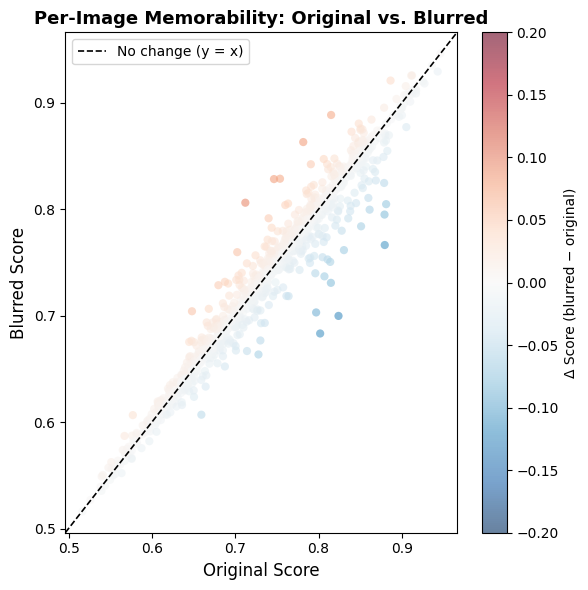
Face Blur
The face blur modification produced a mean delta of −0.0007 (std = 0.0183) across 999 pairs, where a slight majority (51.5%) of images saw an increase in predicted memorability score. These results were not statistically significant (p = 0.259), so we cannot definitively say that the face blur ablation alone is able to influence the memorability prediction in any meaningful way.
Grayscale
With the grayscale modification, we saw a mean delta of +0.0089 (std = 0.0516) across 1,000 pairs, with a majority (55.6%) of these images being predicted as more memorable compared to the unmodified images. Our results were statistically significant (p < 0.0001), meaning this grayscale modification was the only condition that reliably produced an increase in predicted memorability.
Whole Image Blur
Applying a blur across the entire image produced a mean delta of −0.0091 (std = 0.0737) across 1,000 pairs, with a majority (53.8%) of images scoring lower after blurring. Again, our results were statistically significant (p = 0.0001), so this global blurring reliably reduced the predicted memorability scores. However, the relatively high std suggests that the impact of this ablation tended to be particularly variable across image pairs.
Text Blur
The text blur modification produced a mean delta of +0.0001 (std = 0.0172) across 999 pairs, with only a slight majority (52%) of images increasing in predicted memorability scores. This effect was not statistically significant (p = 0.831), so purely blurring out certain text regions cannot be interpreted as having a meaningful impact on predicted memorability.
Crop
Cropping images produced a mean delta of +0.0020 (std = 0.0629) across 1,000 pairs, with a majority (52.2%) of images increasing in predicted score. Once again, this effect was not statistically significant (p = 0.311), indicating that this type of center-cropping was not a major contributor to the model’s memorability predictions.
Summary Table
| Ablation | N pairs | Mean Original Score | Mean Ablated Score | Mean Δ | Std Δ | % Drop | p-value |
|---|---|---|---|---|---|---|---|
| Grayscale | 1000 | 0.7362 | 0.7451 | +0.0089 | 0.0516 | 44.4% | <0.0001 |
| Whole Image Blur | 1000 | 0.7362 | 0.7271 | −0.0091 | 0.0737 | 53.8% | 0.0001 |
| Text Blur | 999 | 0.7360 | 0.7361 | +0.0001 | 0.0172 | 48.0% | 0.831 |
| Crop | 1000 | 0.7362 | 0.7382 | +0.0020 | 0.0629 | 47.8% | 0.311 |
| Face Blur | 999 | 0.7360 | 0.7354 | −0.0007 | 0.0183 | 48.5% | 0.259 |
Qualitative Results
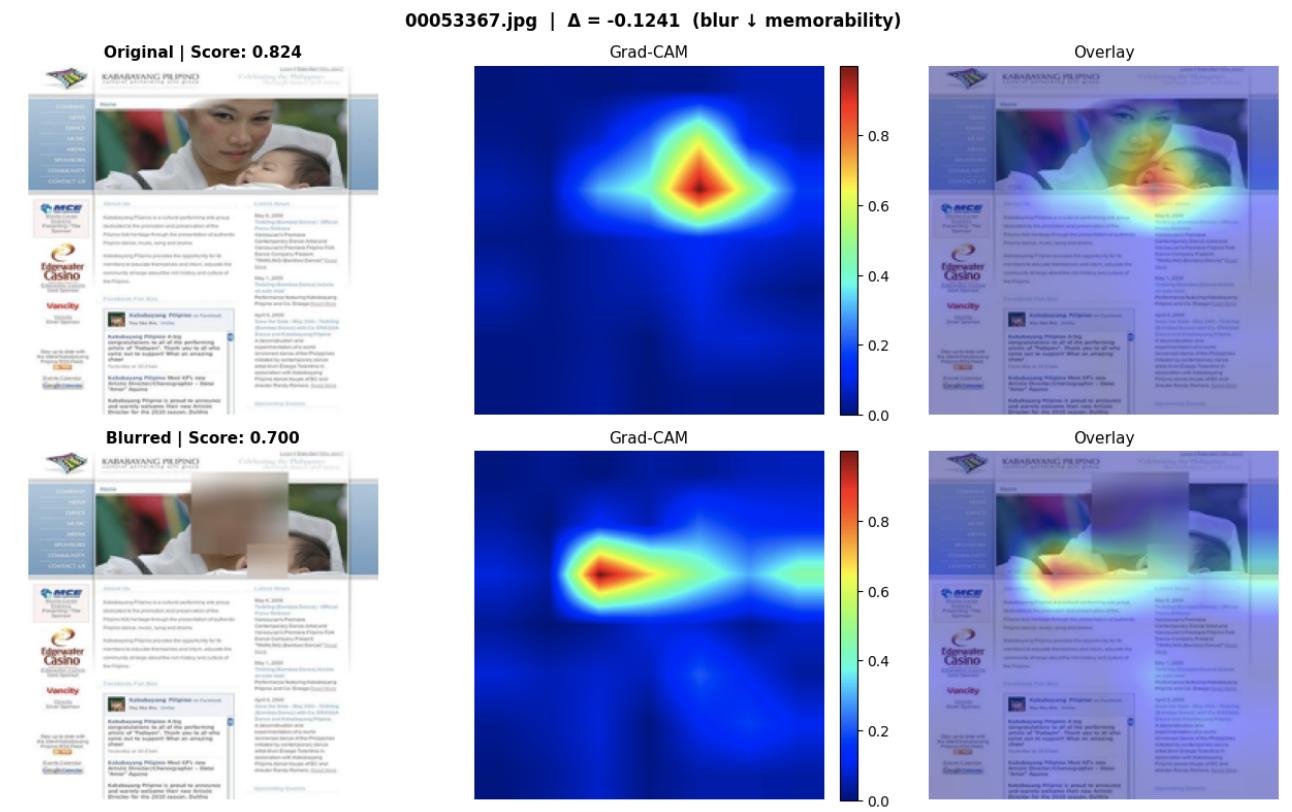
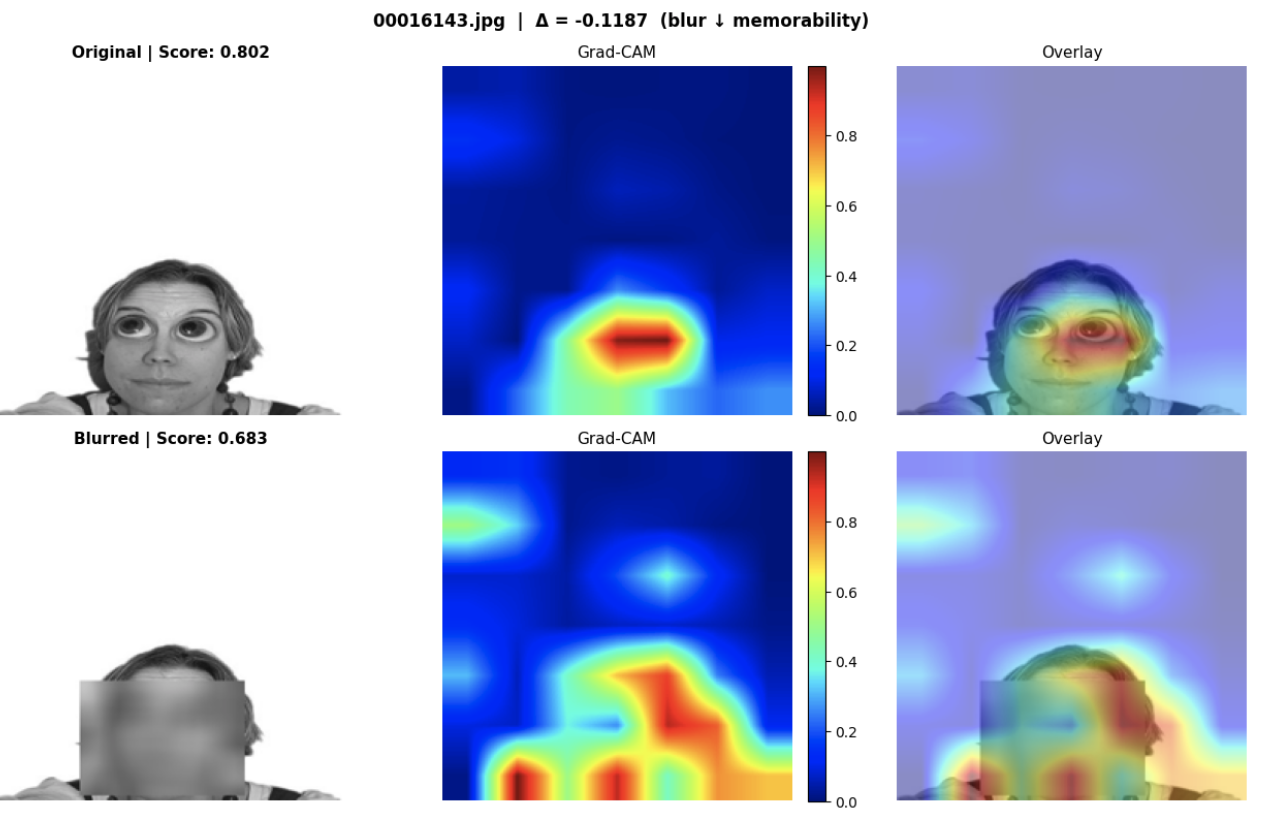
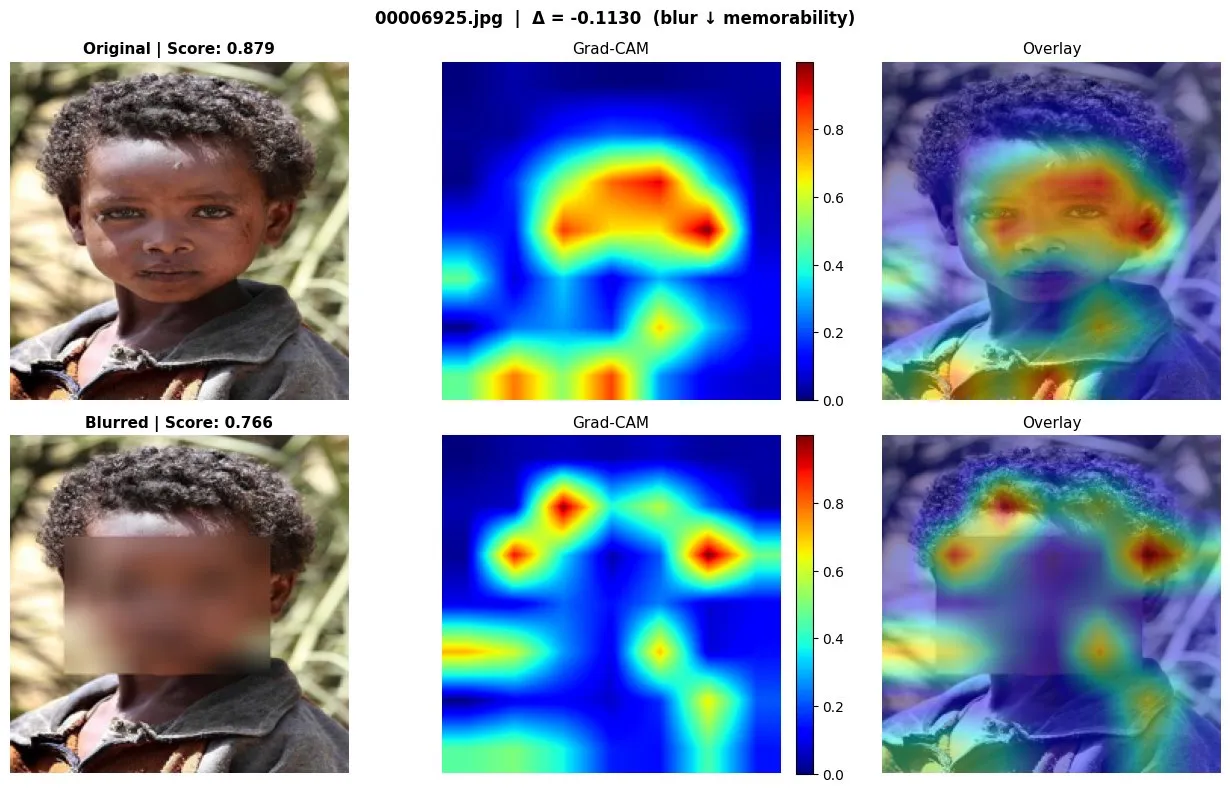
In addition to the statistical comparisons of memory scores before/after ablations were made, we generated Grad-CAM visualizations to see which spatial regions of each image had the most influence on the model’s predicted memory score. For a subset of image pairs, heatmaps were generated for both the original and ablated versions, which were compared side-by-side to determine any consequential shifts in the model’s attention. Warmer regions indicate stronger contributions to the predicted score, while cooler regions indicate weaker contributions to the predicted score. Below are select pairs of these heatmaps comparing model attention in the original images to their face-blurred counterparts:
Discussion
Overall, these ablation results show us that only modifications that altered the more global, low-level properties of the image (i.e. color and sharpness) had a statistically significant effect on predicted memorability, whereas the targeted modifications (i.e. face/text blurring) had no consistent effect. This finding reveals much about what the model learned to associate with memorability during fine-tuning on the LaMem dataset.
There are a few specific results that we found particularly interesting. The first being that grayscale increased predicted memorability, which seems like the most counterintuitive finding based on current literature about image memorability. Perhaps this can be attributed to the ResNet-50 architecture, which was initialized with ImageNet weights that are optimized for lower-level features, and thus are not color-dependent. The whole-image blur modification produced the only other statistically significant result, though in the negative direction. We see a higher standard deviation for this condition compared to grayscale (0.0737 vs. 0.0516), implying that images tend to vary much more in the extent to which they rely on sharpness for these predictions.
Meanwhile, face blur and text blur did not produce significant effects (p = 0.259, p = 0.831) and both mean deltas were essentially negligible (-0.0007 and +0.0001). We can see this plainly in the face blur histogram, which sees a distribution of score deltas tightly centered around zero with very little spread, so blurring out facial regions had no functional bearing on model predictions. This result is also surprising, as human memorability research has consistently found faces to be one of the most memorable visual elements across images. A possible explanation for this discrepancy could be a limitation of the LaMem dataset, where perhaps memorability scores were driven more so by compositional properties rather than by the presence of faces, in which case the model would learn to weigh faces less. However, the lack of effect from text blur may not be as surprising, since text is not generally considered a key driver of image memorability. This is supported by a tiny mean delta (+0.0001) and tight standard deviation (0.0172), indicating that the model does not consider text regions consequential. On the whole, these quantitative results suggest that the model does not chiefly rely on the same memorability drivers that humans do, which is the key insight that we were looking to draw; the model’s predictions, on an aggregated level, were determined mostly by ablations that affected global, low-level features.
Given the unexpected statistical results for the face blur ablation, we were mostly curious about the heatmap considerations for this condition. In the heatmaps above, we see that attention is more directly focused on the faces in the original images, and after blurring, attention is scattered to non-facial regions, with predicted scores dipping substantially. For these images, where the face was the dominant subject, we reasonably expect the model’s attention to fragment in this manner after blurring, thus suggesting that the model does in fact rely on facial representations for its predictions in these cases. These observations tell us that the aggregate result for the face blur condition, namely a mean delta = -0.0007 and p-value = 0.259, does not tell us the entire story, since there appears to be noticeable variation on the image level that isn’t accounted for using just summary statistics.
Limitations
There are four main limitations to our model. They are summarized below:
The Scope of the Model
The CNN we trained is deliberately simple - a fine-tuned ResNet-50 on 1,000 LaMem images. Real-world systems that predict what content sticks (social media engagement models, ad-targeting pipelines) are vastly more complex, incorporating user behavior, temporal dynamics, and feedback loops we simply cannot replicate here. Our results should be read as a controlled probe of one model’s behavior, not a general claim about how memorability prediction works at scale.
The Scope of the Data
LaMem itself constrains what we can claim. Its memorability scores are averaged across many participants without demographic information, so our model implicitly assumes memorability is uniform across people. In reality, age, cultural background, and prior experience all shape what we remember. The dataset also captures only short-term recognition of static images, which is a narrow slice of how human memory actually works. The 1,000-image subset we used further limits subgroup analyses (e.g. portrait-heavy vs landscape-heavy images), so some of our null results may simply be underpowered.
The Scope of the Ablations
Each ablation was applied in isolation, leaving interaction effects untested. We don’t know, for instance, whether grayscale + crop combined would behave differently than either alone. Our face-blur method also preserves the spatial footprint of the face (its shape, skin tone, and rough position), which means the model may still detect a face-shaped region after blurring. This likely underestimates the true contribution of facial features to memorability, so the null result for face blur should be read with that caveat in mind.
No Human Benchmark
Finally, all memorability scores in this analysis are model-predicted rather than directly human-rated. Our findings therefore describe what ResNet-50 learned to associate with memorability on LaMem - which may not fully match what a human observer would actually remember. Closing this gap would require running a parallel human memory experiment on the same ablated images, which is outside the scope of this project but a clear next step.
Was AI Needed?
Image memorability is dependent on an array of visual features interacting with one another, including color, composition, text, objects, faces, and overall scene context. Together, these relationships are highly complex and difficult to describe manually.
Using purely statistical methods would not have been as effective for this project because they would have required us to define and measure every important feature beforehand. For example, we could have built a regression model using variables like whether a face was present, how colorful the image was, or how blurry it appeared. However, this approach assumes that memorability can be explained through a relatively small set of predefined features and simple relationships between them that we already know.
Our project results show that memorability is more complicated than that. We originally hypothesized that semantic features such as faces would matter strongly, but instead, broader global image qualities such as image sharpness appeared to have a larger overall effect than we initially expected. This demonstrates why manually defining rules for memorability would be difficult.
Convolutional neural networks (CNNs) were therefore needed for this project because they can automatically learn complex visual patterns directly from the dataset. Instead of being explicitly told exactly which features mattered the most, the model learned which combinations of visual information were most useful for predicting memorability through training.
What We Would Do With Three More Months
If we had three more months to work on this project, we would primarily focus on expanding the interpretability and experimental portions of the study. Outside our current ablations, there are still many additional visual factors that could be explored. For example, we could test features such as object removal, background replacement, lighting normalization, or combinations of multiple ablations together to better understand how different visual features interact to influence memorability predictions.
We could also improve the quality of our current ablations. For example, our face blur experiments still preserved the rough structure and position of faces, so the model may still have recognized face-like information after blurring. With more time, we could use more advanced techniques such as inpainting or object removal models to fully replace semantic regions in a more realistic way.
Another focus could be on expanding the scale of the project by training on a larger portion of the LaMem dataset (instead of 1,000 images) for more epochs, and experimenting with more advanced architectures such as Vision Transformers or EfficientNet models. This would help us determine whether our findings were specific to ResNet-50 or if they reflected broader patterns in memorability prediction models.
We could also perform a more detailed category-level analysis by separating categories such as portraits, landscapes, indoor scenes, advertisements, and object-centered images to determine whether memorability drivers differ across different types of images. It is possible that some effects could currently be averaged out across categories and are masking stronger relationships within specific groups of images.
With even more time, we could also explore a more direct comparison between the model’s behavior and human perception. Using our CNN’s memorability predictions, an important next step would be testing whether the same ablations produce similar effects on actual human memory performance. This would help us determine whether the model is truly learning human-like memorability patterns or relying on shortcuts specific to the training dataset, ultimately helping answer broader questions such as: What visual information does the human brain prioritize when forming memories, and does AI learn to encode images the same as humans?
Ethics
There is an old advertising proverb, often attributed to John Wanamaker: “Half the money I spend on advertising is wasted; the trouble is, I don’t know which half”. For a century, that sentence has been the cost of doing business in attention - which half worked was something you only ever found out after the cheque had been cleared. A memorability model collapses that timeline. A score before the campaign launches. A heatmap showing which face the eye locks onto. A blurred-face comparison telling you which one to keep and which one to drop. The technology our project builds towards, in its mature form, is a machine that knows in advance which images will lodge in human minds and which will slide off. That promise is also where the ethics begin, and they begin earlier than most discussions of AI bias admit.
Consider what our own results actually showed. The model didn’t appear to depend strongly on faces to predict memorability. It didn’t appear to depend strongly on text. What it needed was sharpness, contrast, and a certain monochrome aesthetic - the documentary, the high-contrast, the black-and-white. The deeper problem with that kind of shortcut isn’t that it fails; it’s that it sometimes doesn’t. A model exploiting an aesthetic cue would appear to work on every metric the engineering team checks, while quietly enforcing the visual norms of whoever assembled the training set. Deployed at scale, that isn’t neutral optimisation; it’s a slow homogenisation of the visual world toward whatever the data over-rewarded.
The case for building a tool like ours is real - there are messages about smoking, evacuation protocols, and war that genuinely need to stick. Improving the efficiency of production across these contexts with such tools is an objectively worthwhile endeavor. But the case for deploying one, as it stands, is far weaker. What our project produces is not a system that should be making decisions about what billions of people see. It is a working instrument for asking the question that has to come first: what, exactly, is the model rewarding when it says an image is memorable? In our case, the answer was already strange enough - a sharpness preference, a grayscale bias - to argue that nobody should deploy these systems before that question is asked carefully, every time, on every dataset. Image memorability is a domain that matters too much to outsource to machine learning instantiations like this without a robust understanding of the underlying mechanisms, which will only result from further research.
References
Bainbridge, Wilma A., Phillip Isola, and Aude Oliva. ‘The Intrinsic Memorability of Face Photographs’. Journal of Experimental Psychology: General (US) 142, no. 4 (2013): 1323–34. https://doi.org/10.1037/a0033872.
Brady, Timothy F., George A. Alvarez, and Viola S. Störmer. ‘The Role of Meaning in Visual Memory: Face-Selective Brain Activity Predicts Memory for Ambiguous Face Stimuli’. Research Articles. Journal of Neuroscience 39, no. 6 (2019): 1100–1108. https://doi.org/10.1523/JNEUROSCI.1693-18.2018.
Bylinskii, Zoya, Phillip Isola, Constance Bainbridge, Antonio Torralba, and Aude Oliva. ‘Intrinsic and Extrinsic Effects on Image Memorability’. Vision Research, Computational Models of Visual Attention, vol. 116 (November 2015): 165–78. https://doi.org/10.1016/j.visres.2015.03.005.
Dubey, Rachit, Joshua Peterson, Aditya Khosla, Ming-Hsuan Yang, and Bernard Ghanem. ‘What Makes an Object Memorable?’ 2015 IEEE International Conference on Computer Vision (ICCV), December 2015, 1089–97. https://doi.org/10.1109/ICCV.2015.130.
Geirhos, Robert, Jörn-Henrik Jacobsen, Claudio Michaelis, et al. ‘Shortcut Learning in Deep Neural Networks’. Nature Machine Intelligence 2, no. 11 (2020): 665–73. https://doi.org/10.1038/s42256-020-00257-z.
Isola, Phillip, Jianxiong Xiao, Devi Parikh, Antonio Torralba, and Aude Oliva. ‘What Makes a Photograph Memorable?’ IEEE Transactions on Pattern Analysis and Machine Intelligence 36, no. 7 (2014): 1469–82. https://doi.org/10.1109/TPAMI.2013.200.
Isola, Phillip, Jianxiong Xiao, Antonio Torralba, and Aude Oliva. What Makes an Image Memorable? 2011.
Kanwisher, Nancy, Josh McDermott, and Marvin M. Chun. ‘The Fusiform Face Area: A Module in Human Extrastriate Cortex Specialized for Face Perception’. Articles. Journal of Neuroscience 17, no. 11 (1997): 4302–11. https://doi.org/10.1523/JNEUROSCI.17-11-04302.1997.
Khosla, Aditya, Akhil S. Raju, Antonio Torralba, and Aude Oliva. ‘Understanding and Predicting Image Memorability at a Large Scale’. 2015 IEEE International Conference on Computer Vision (ICCV), December 2015, 2390–98. https://doi.org/10.1109/ICCV.2015.275.
Kramer, Max A., Martin N. Hebart, Chris I. Baker, and Wilma A. Bainbridge. ‘The Features Underlying the Memorability of Objects’. Science Advances 9, no. 17 (2023): eadd2981. https://doi.org/10.1126/sciadv.add2981.
Lahner, Benjamin, Yalda Mohsenzadeh, Caitlin Mullin, and Aude Oliva. ‘Visual Perception of Highly Memorable Images Is Mediated by a Distributed Network of Ventral Visual Regions That Enable a Late Memorability Response’. PLOS Biology 22, no. 4 (2024): e3002564. https://doi.org/10.1371/journal.pbio.3002564.
Needell, Coen D., and Wilma A. Bainbridge. ‘Embracing New Techniques in Deep Learning for Estimating Image Memorability’. Computational Brain & Behavior 5, no. 2 (2022): 168–84. https://doi.org/10.1007/s42113-022-00126-5.
Perera, Shay, Ayellet Tal, and Lihi Zelnik-Manor. ‘Is Image Memorability Prediction Solved?’ 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), June 2019, 800–808. https://doi.org/10.1109/CVPRW.2019.00108.
Perera, Shay, Ayellet Tal, and Lihi Zelnik-Manor. ‘Is Image Memorability Prediction Solved?’ arXiv.Org, 31 January 2019. https://arxiv.org/abs/1901.11420v1.
Vokey, John R., and J. Don Read. ‘Familiarity, Memorability, and the Effect of Typicality on the Recognition of Faces’. Memory & Cognition 20, no. 3 (1992): 291–302. https://doi.org/10.3758/BF03199666.
Wakeland-Hart, Cheyenne, and Mariam Aly. ‘Predicting Image Memorability from Evoked Feelings’. Behavior Research Methods 57, no. 1 (2025): 58. https://doi.org/10.3758/s13428-024-02510-4.
Zech, John R., Marcus A. Badgeley, Manway Liu, Anthony B. Costa, Joseph J. Titano, and Eric Karl Oermann. ‘Variable Generalization Performance of a Deep Learning Model to Detect Pneumonia in Chest Radiographs: A Cross-Sectional Study’. PLOS Medicine 15, no. 11 (2018): e1002683. https://doi.org/10.1371/journal.pmed.1002683.